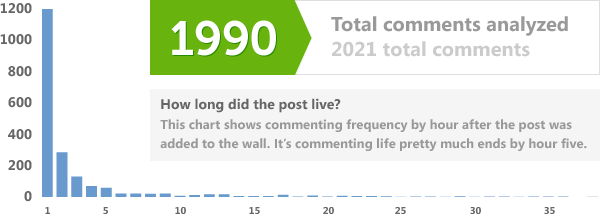
HTC recently posted to their Facebook wall a simple question: “How many mobile phones have you owned?” Within a day they received about 2000 answers. Using the Facebook’s Graph API I wondered how hard it would be to automate the analysis to find out the average number.
Here is the result:

Note: I removed about a dozen responses that stated ownership of more than 500 mobile phones. While this is probably feasible, it was a small minority and skewed my results too much.

Previous Manufacturer In most cases, the owner upgraded from a phone by one of these makers to an HTC. As such, these are the “losers”, with Nokia coming out worst. |
Current Model Commenters more readily their shared current model. As expected, most of these are HTCs, though some commenters left HTC for a new maker. |

 | |
Comments by User Gender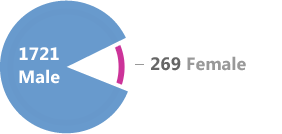 While expecting a male bias, I didn’t expect it to be so one-sided. I’m interested to know if the page demographics are similarly skewed. |
Comments by Locale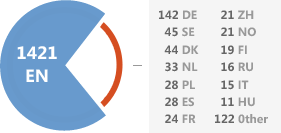 Facebook doesn’t provide location for un-authenticated requests. Fortunately, locale is a useful proxy. (EN includes US and GB) |
Comments by SentimentThis measures the sentiment toward HTC and their products, not the sentiment of the comment. The sentiment was reviewed manually, so the accuracy is quite high. However, the small sample-size should discourage reading too much into this set of results.  |

The process for this was actually quite straight-forward. First I used the Facebook Graph API to download all the comments into a database. Because I didn’t want to manually review 2000 comments, my first pass automatically checked for comments containing only numbers. This took only a few minutes to code and knocked out 400 comments.
I then selected very short messages with the assumption that they were just numerical answers with punctuation. This proved prescient since many people noted the number of phones they’d owned and appended smiley faces. This took care of another 250 or so messages. To review the final set, I coded a small web application to manually step through each comment. Through this application I could also note the comment sentiment, past and current phones, and other facets. After some refinement to the app, I was able to review about a dozen messages a minute and complete the entire review in less than two hours.

I looked at several other Facebook posts with a large number of comments, but choose this one because many of the answers would be uniquely easy to automatically parse. If the question required a prose response, the analysis would need to be done more manually, which would be quite time-consuming. Crowd sourcing could provide a solution, perhaps through something like Amazon’s Mechanical Turk.
Because I coded the web application solely for this topic, I was able to very specific in my search parameters, which allowed for some interesting insights. For example, it was fascinating to see people’s ownership history (especially how their brand-loyalty has evolved over time). Similar analysis using an off-the-shelf tool (Sysomos, Radian 6, etc) would not have provided this level of customization and granularity.
Impressive. Most impressive. :-)
Polish the website further and you may have a product you can sell.
Very interesting project and findings. There is no doubt that without the ability to mine data, even on the most basic level, the business person is ill equipped to function in the World according to Web 2.0.
interesting findings and project.